Building a Résumé-Parsing Workflow with Taylor
As long as there's been applicant-tracking systems (and probably longer!), résumé parsing has been both necessary, and a major pain. Challenges range from marshaling text from a mangled PDF into usable text, to normalizing the 10 different names for the same college to a single canonical identifier. The market is dominated by legacy systems that pretty much everyone agrees are no good. It's about time to shake things up.

Click here to try our résumé parsing demo!
At Taylor, we've been working on powerful tools for classification and entity resolution. In this post, we're excited to share how to bring these to bear on this challenging, real-world task. The result, though far from perfect, is a practical solution, and a great demonstration of the power of combining classification and entity extraction primitives into an end-to-end workflow. Let's dive in.
Extracting Structured Data
Most of the time, résumé parsing begins with a PDF. The PDF is a nightmarish file format, and probably should not exist. But it's also how we've all collectively decided to exchange résumés, so we're kind of stuck with it. For our extraction step, we're not doing anything fancy—we define a schema in Pydantic, and then use a language model to extract the schema. LLMs are good enough at this now that we can pretty much just ask for what you want, and get it back.
import json
from pydantic import BaseModel, Field
from typing import Optional
class EducationItem(BaseModel):
school: str
field_of_study: str
start_year: Optional[str] = Field(None, description="Start year, in YYYY format.")
end_year: Optional[str] = Field(None, description="End year, in YYYY format.")
class WorkHistoryItem(BaseModel):
employer: str
job_title: str
start_year: Optional[str] = Field(None, description="Start year, in YYYY format.")
end_year: Optional[str] = Field(None, description="End year, in YYYY format.")
class Resume(BaseModel):
name: Optional[str]
email: Optional[str]
education: list[EducationItem]
work_history: list[WorkHistoryItem]
skills: list[str]Open-source libraries like Instructor (opens in a new tab) allow you to take these schemas and enforce them on the outputs of a language model. Or, you can forego fancy tooling altogether and just stuff the schema into your prompt:
prompt = (
"Please extract the following JSON schema from the resume text below.\n\n" +
"```json\n" +
json.dumps(Resume.model_json_schema(), indent=2) +
"\n```\n\n" +
resume_text
)As for getting the résumé text—if the PDF is not too mangled, PyMuPDF (opens in a new tab) is a great tool for simply extracting the text from it to feed it to the language model. For more challenging résumés, it might work better to convert the PDF to an image, then perform OCR (or send the image directly to a multimodal language model). However, in our tests, we found that sending an image to multimodal LLMs like GPT-4o or Claude led to hallucinations, so we stuck with raw text extraction for our demo.
Resolving College Names and Fields of Study
After extracting these fields from the résumé (if all goes well), we have a beautiful blob of JSON with all the data. We could call it quits here—but there are a few more problems. The main one is that people like to describe the same thing with lots of different aliases. As a recruiter or job board, I want UC Berkeley, Cal, and Berkeley to all refer to the same thing. I also don't really care about the fine-grained differences between EECS and Computer Science—companies looking for one are probably fine with the other.
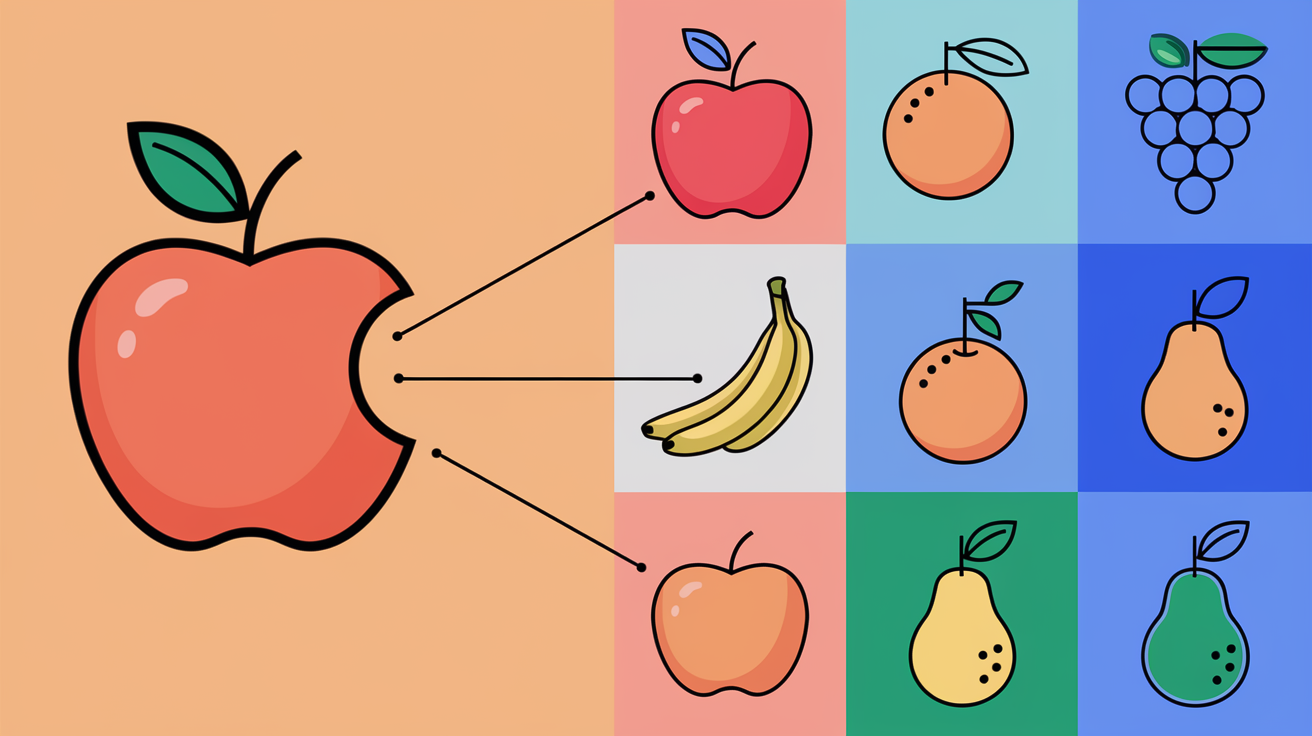
The process of mapping these aliases to a single name is known as "entity resolution"—you can also think of it as a deduplication step. We start with an exhaustive taxonomy of all the possible values, and then use natural language processing to identify the best candidate (or None if the entity is not present). At Taylor, we use a combination of fuzzy string matching (still state-of-the-art for many problems!), embedding similarity, and small-language-model verification to provide high-quality entity resolution in our API.
Getting started with the API is easy—we offer 1000 requests for free, and once you've made an account and created an API token, entity resolution is a simple POST request away:
import requests
api_key = "xx-your-api-key-here"
res = requests.post(
"https://api.trytaylor.ai/api/entities/resolve",
headers={"Authorization": f"Bearer {api_key}"},
json={
"pipeline_name": "taylor:global_universities",
"texts": [
"UC Berkeley",
"University of California, Berkeley",
"Berkeley"
],
}
)
print(res.json())Classifying Jobs by O**NET-SOC Codes
There's a similar issue with job titles—lots of similar jobs are referred to in slightly different ways, making it hard to group and categorize them accurately. For instance, Software Developer, Computer Programmer, and Software Engineer all do roughly the same thing and would be interested in similar jobs.
A common taxonomy for categorizing job roles is the O*NET-SOC taxonomy, a standardized set of job titles used by the US government. Taylor's API provides a classifier for this taxonomy, which can take in job titles or descriptions and return the appropriate O*NET-SOC code.
import requests
api_key = "xx-your-api-key-here"
res = requests.post(
"https://api.trytaylor.ai/api/public_classifiers/predict",
headers={"Authorization": f"Bearer {api_key}"},
json={
"model": "job_postings_onet",
"texts": [
"Software Developer",
"Computer Programmer",
"Software Engineer"
],
"threshold": 0.5,
"top_k": 1
}
)
print(res.json())To apply this to an extracted résumé, we just take each job in the work_history field, and pass it through the classifier. The classifier will return the O*NET-SOC code for the job, along with a confidence score. We can add these enriched job codes back to the résume object.
Future Directions
In this post, we've shown how to use building blocks from Taylor's API to build a practical résumé parser. Of course, this is just a first pass. Starting from here, you could layer on our models for resolving cities, extracting job skills, identifying company names, and more.
We're also excited to bring tooling for building these workflows directly to our users. Right now, we have individual models on the API, and you're responsible for piecing them together. This résumé parsing demo is the first test-drive of our new workflow engine, which allows users to build declarative workflows composed of multiple models, like the following:
tasks:
- name: field_of_study_entity
input_field: "$.education[*]"
input_template: "{{ data.field_of_study }}"
transform: "taylor:field_of_study"
- name: job_codes
input_field: "$.work_history[*]"
input_template: "{{ data.job_title }}"
transform: "taylor:job_postings_onet"If the résumé parser piqued your curiosity, and you're already imagining your own awesome multi-step workflow, please get in touch (opens in a new tab). We'll be releasing workflows to select users in alpha over the coming months, and we'd love to work with you.